What It’s All About?
Probably, you found this post while searching for methods of stock prediction. Spoiler: in this article, I will not introduce a fascinating model that will make a lot of money for you. On the contrary, I want to focus on the wrong approaches and techniques that some data scientists may fall into.
You can find hundreds of posts on the internet when somebody using a single LSTM unit obtains 95%+ precision in market prediction. I scrutinized the most popular articles and checked the authors’ results. Here, I check: are they really that good.
Simple models – beautiful results
Sounds cool, right? In most cases, simple models can lead to fascinating outcomes, but the stock prediction is definitely not the case.
Searching for “Stock prediction with LSTM,” you’ll encounter numerous posts showing how simple LSTM-based models can achieve magic results. Here’s usual traps:
1. LSTMs are powerful
If you encounter this kind of architecture:
regressor = Sequential()
regressor.add(LSTM(units = 50, return_sequences = True, input_shape = (X_train.shape[1], 1)))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout(0.2))
regressor.add(LSTM(units = 50))
regressor.add(Dropout(0.2))
regressor.add(Dense(units = 1))Run.
Models with 3+ LSTM layers already considered as big models that can do amazing things. Andrej Karpathy in his blog was able to generate C code that almost compiles using just 3 layers of LSTM He needed about 474 Mbytes of code to not overfit the model. I know that the capacity of the model highly depends on the number of LSTM hidden units but usually, 4 layers of LSTM are redundant and you need an enormous dataset to not overfit your model.
In the article that I cited above, the author uses 4 layers and trains model on about 1500 samples. No need to talk that model will overfit. However, the author demonstrates amazing results:
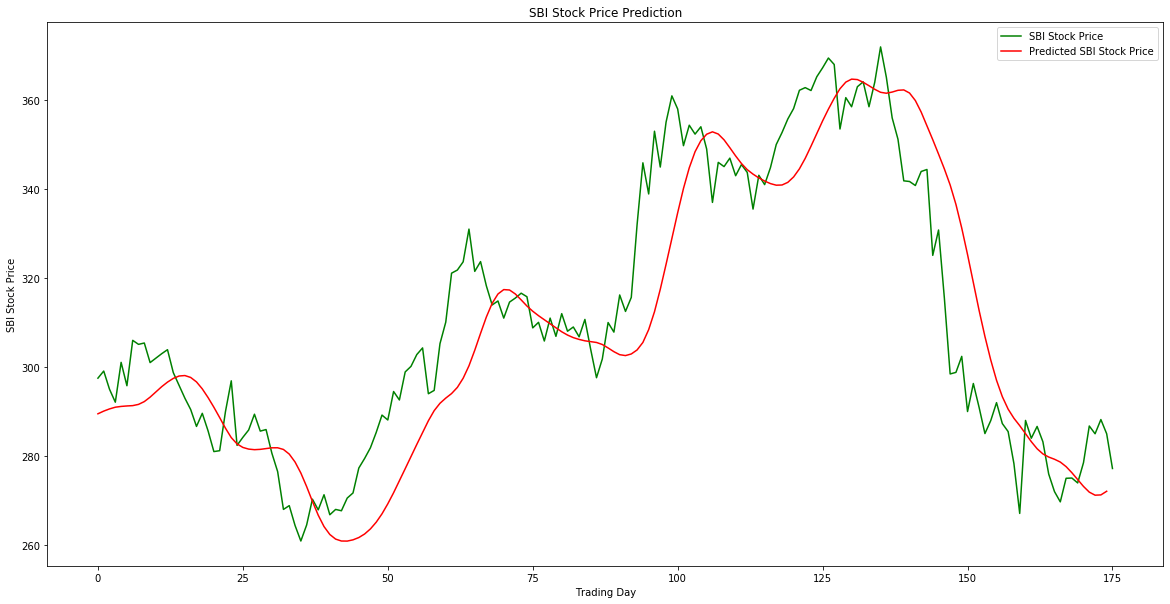
In the first view, the perfomance is really good. But is it really useful? It looks like the model approximates one of the exponentially weighted moving averages. Moreover, if you look at the graph at some specific point, you’ll notice that the predicted data give you little to no information about stock price movemnts.
Another thing that is noticeable is the severe left shift of predictions. You’ll say: “Just shift it left and they will match.” Unfortunately, no. In this case, we will not obtain any relevant data that can predict future prices. Moreover, this “shift” behavior can be due to the fact that in the author’s solution, the model makes approximations, basing on the recent 60 values. Look at the explanation:
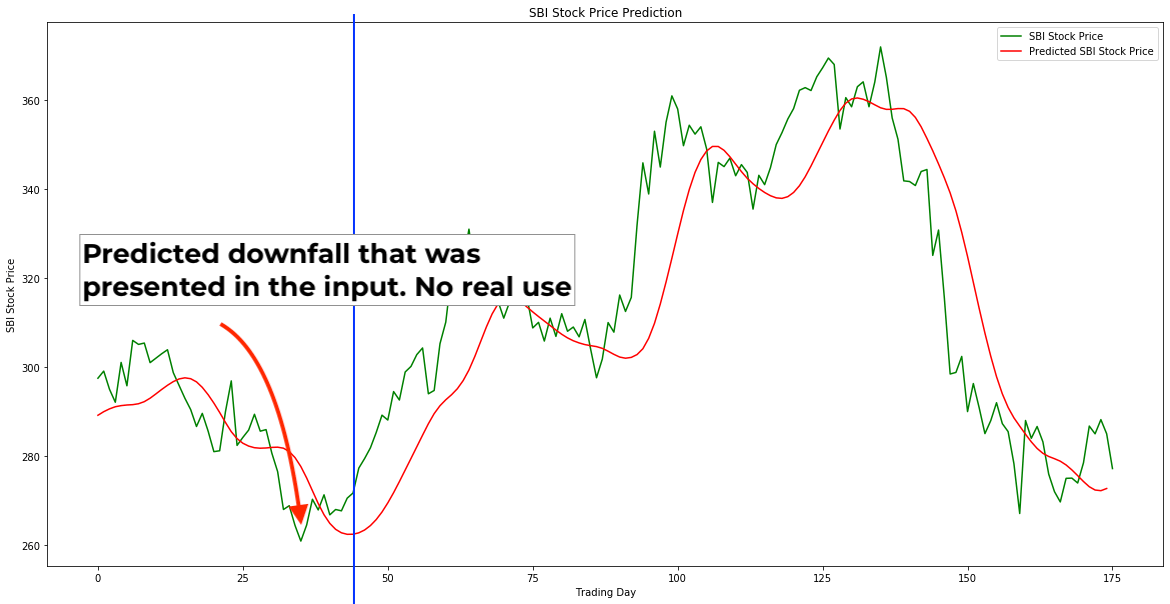
This article will be updated when I find another problematic researches.


