The Issue Must Not Be That Bad
That's what I thought when I encountered a PyTorch problem during one of my college assignments. Jupyter kernel was dying because of some bug in the LSTM implementation for MPS.
After a quick investigation, I discovered that this happens because of the batch_first flag. MPS's backend did not work correctly with it and crushed the entire kernel.
"Easy fix"
P.S. After that phrase, Alex spend the next two days fixing what looked like an "easy fix"
PR was merged pretty quickly. Thanks, PyTorch team, for that! And the story could've ended here, but I discovered a funny detail in MPS tests.
@unittest.skipIf(True, "Backward of lstm returns wrong result")
def test_lstm_2(self, device="mps", dtype=torch.float32)And LSTM was really bad. It got a whole lot worse score than when trained on CUDA or CPU.
It Was Bad. Really Bad
It turned out that LSTM on MPS was completely broken. The forward pass had a bug with the batch_first flag and hidden cell initialization.
Backward pass used first layers weights for the last layers, mixing up all gradients. It did not calculate gradients for hidden states. And my favourite: the backward function returned initialized with garbage tensors, screwing up all subsequent training. It was a mess that I kept investigating for several days.
Eventually, I fixed LSTM and its tests in a massive PR, ensuring that it is consistent with the CPU.
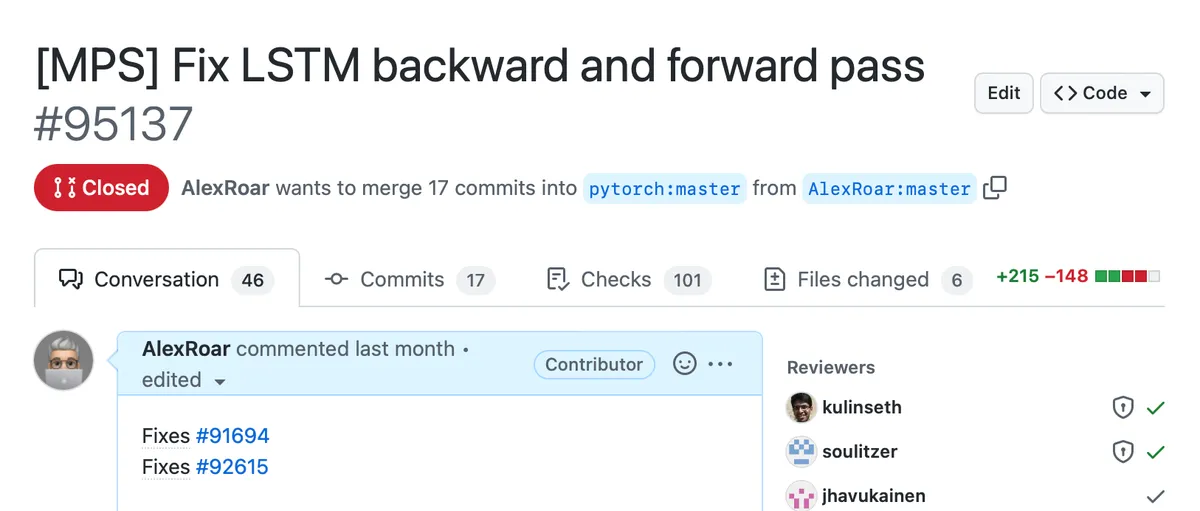
What I Learned
- Big projects also have garbage code. Broken implementation lived in stable releases for almost a year, generating several related GitHub issues.
- Contributing to a big project is fun and challenging. And it eventually helps a lot of developers, which keeps me warm during cold winter nights. Specifically, contributing to PyTorch is extremely simple. Thanks, PyTorch team, for arranging that!
- Deploying untested code that looks right is extremely dangerous. I listed pretty severe mistakes that I found scrutinizing LSTM sources for several days. There's no way they could have been discovered without extensive testing. Even though the issues were severe, they were also subtle. The code looked right.
Finally
I was able to complete the college PyTorch assignment even though it required rewriting PyTorch's LSTM MPS implementation. Consider also solving open issues of your favourite framework or project. At the end of the day, it is a lot more fun than Leetcode problems.
Subscribe to Alex Dremov
Get an email every time I post something. No SPAM.
See My Work
 pytorchpytorchpytorchpytorch
pytorchpytorchpytorchpytorch